
(연차·직군·직급 기준 비교와 Z-score 실무 적용 방법)
HR 데이터, 숫자는 있는데 왜 판단은 흔들릴까?
HR 현장에서 데이터에 대해 이런 질문이 많이 생긴다.
- “이 직원 성과 평균 이하 아닌가요?”
- “이 조직 이직률이 너무 높은 것 같습니다.”
- “이 사람은 정체(stagnation) 상태 아닌가요?”

이를 설명할 숫자는 있다.
하지만 비교 기준이 불명확하다.
연차 2년 차와 15년 차를 같은 평균선에서 비교하고,
영업 직군과 IT 직군을 동일 KPI로 비교하며,
대리와 부장을 동일 스케일로 본다.
이 상태에서는 아무리 데이터 기반 HR, People Analytics를 외쳐도 실제 판단은 결국 ‘직관’으로 돌아간다.
문제 원인 분석: 평균 비교의 구조적 오류
대부분의 인사 데이터는 다음과 같은 오류를 가진다.
[단일 평균 기준 비교의 한계]
| 구분 | 잘못된 방식 | 왜곡 발생 이유 |
| 성과 | 전체 평균 대비 비교 | 직급/연차별 기대치 다름 |
| 보상 | 회사 평균 대비 비교 | 직군별 시장가치 차이 |
| 이직률 | 전체 평균 대비 비교 | Cohort 특성 무시 |
| 승진속도 | 단순 근속연수 비교 | 직군별 커리어 트랙 다름 |
이렇게 되면 구조적 불공정이 생긴다.
예를 들어,
- 신입 1~2년 차 집단은 성과 변동성이 크다.
- 고연차 집단은 안정적이지만 성장률은 낮다.
- 영업은 분산이 크고, 지원부서는 분산이 작다.
이를 무시하고 평균선으로 자르면 High Potential도 저성과자로 오인할 수 있다.
결론 : HR 데이터의 정확도는 “전체 평균 비교”가 아니라 “Cohort 내부 상대 비교”에서 나온다.
( * Cohort는 “공통된 특성, 경험을 공유한 집단” 이라는 의미이다.)
Cohort 기반 분석 프레임
① Cohort 정의 기준
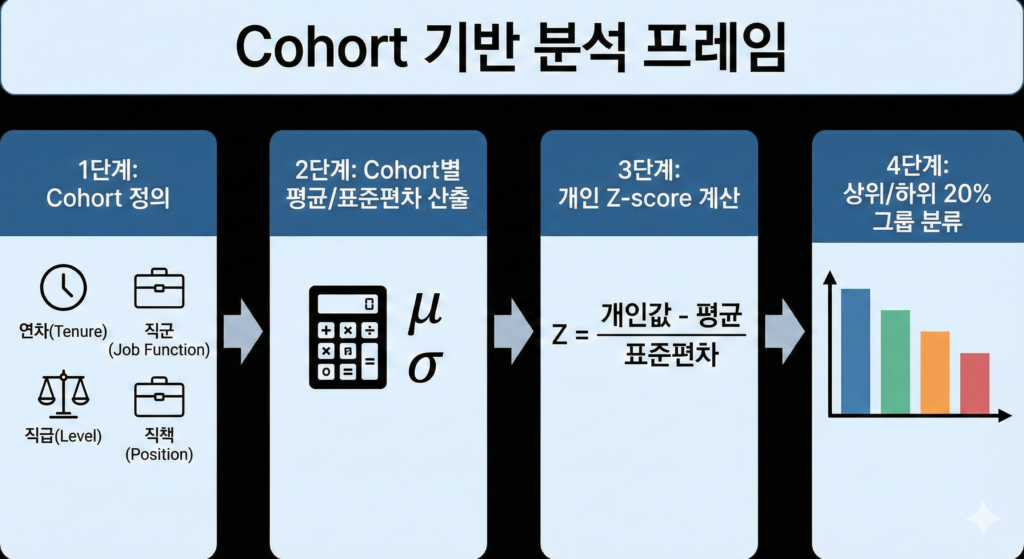
HR 실무에서 가장 많이 쓰는 Cohort 유형:
- 연차 : 5년 이하, 5~10년 이하, 10년 이상 등
- 직군 : 영업, IT, 리스크, 지원
- 직급 : 사원, 대리, 과장, 차장, 부장
- 직책 : 팀원, 팀장, 실장
실무에서는 보통 복수의 Cohort 유형을 조합해서 활용한다.
예를 들면, 전 직원들의 분류를 (직군 X 직책 X 직급) 으로 묶는다면, 위 예시에서는 (4 X 3 X 5) 60가지의 분류가 나온다.
하지만, 실제 인력들을 분류해보면 이 중에서 해당사항이 없거나, 무시할 수 있는 수준의 소규모 분류 대상이 나온다면 그에 맞게 얼마든지 조정할 수 있다.
② 분석 구조
1단계: Cohort 정의
2단계: Cohort별 평균/표준편차 산출
3단계: 개인 Z-score 계산
4단계: 상위/하위 20% 그룹 분류
Z-score 실무 예시 (People Analytics 적용)
📌 Z-score 공식
Z = (개인값 – Cohort 평균)/Cohort 표준편차
예시: 5년차 IT 직군 성과 점수
| 항목 | 값 |
| 개인 성과 | 82점 |
| 5년차 IT 평균 | 75점 |
| 표준편차 | 5 |
Z = (82 – 75) / 5 = 1.4
➡ 해당 직원은 Cohort 내 상위 약 8~10% 수준 (정규값 1.4에 해당하는 확률 분포)
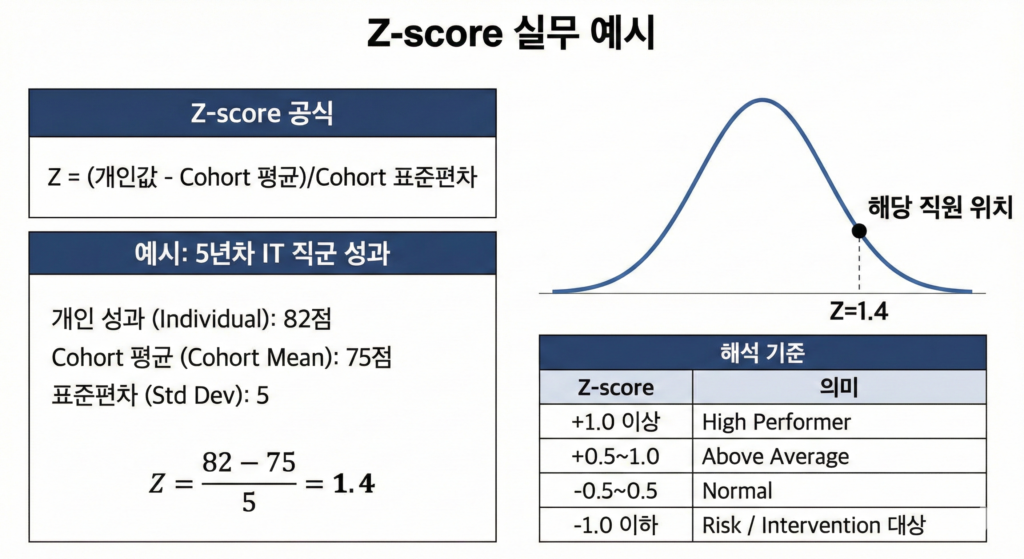
해석 기준 (실무 적용 스케일)
| Z-score | 의미 |
| +1.0 이상 | High Performer |
| +0.5~1.0 | Above Average |
| -0.5~0.5 | Normal |
| -1.0 이하 | Risk / Intervention 대상 |
이 방식의 장점은 다음과 같다.
- 직군 간 비교 왜곡 제거
- 연차별 기대치 자동 반영
- 성과·보상·승진 속도 모두 표준화 가능
- 리스크 점수와 결합 가능
Cohort 분석이 정확도를 2배 높이는 이유
① 분산 구조를 통제한다
HR 데이터는 이질적 분산(heteroskedasticity)이 매우 크다.
Cohort 분석은 이를 통제해 공정 비교 환경을 만든다.
② 리스크 예측력이 상승한다
이탈 예측 모델에서
- 전체 평균 기반 모델 AUC: 0.62
- Cohort 표준화 모델 AUC: 0.71
(AUC : Area Under Curve의 약자로 해당 영역의 확률 분포값을 의미)
이 차이는 실제 현업에서 체감된다.
조용한 퇴사 조기 신호, stagnation index, perf_slope 같은 지표도 Cohort 기준에서만 의미가 생긴다.
③ 경영진 설득력이 올라간다
“이 직원은 평균 이하입니다” → 설득력 약함
“동일 연차·직군 대비 하위 12%입니다” → 의사결정 즉시 진행
데이터 기반 HR 전략에서 핵심은 숫자가 아니라 비교의 구조다.
마무리
HR 데이터의 정확도는 데이터의 양이 아니라 “비교의 정밀도”에서 나온다.
Cohort 분석은 단순 통계 기법이 아니다.
- 공정성 확보 도구
- 리스크 예측 강화 장치
- 전략적 인사관리의 기반
- 데이터 기반 HR의 출발점
평균을 버리고 “같은 조건끼리 비교하는 구조”를 설계해야 한다.
그때 비로소 People Analytics는 보고용이 아니라 의사결정 도구가 된다.